
The Future • April 2021
Blog Post
It was a lightbulb moment during lockdown; a few days after the team completed a piece of work, it suddenly hit me. Online posts from Twitter, Facebook, Instagram, blogs, forums, news, reviews and videos were fused with call centre audio files and survey verbatims in just 3 days, done for the first time and done right. Albeit from very different sources, involving both solicited and unsolicited opinion, this data had something in common - it was all unstructured data.
For the uninitiated market researcher or data cruncher unstructured data exists in different formats such as:
Structured data on the other hand is numbers in tables such as:
When I compare the amount of effort that is required to integrate structured data, with what we experienced integrating text and audio (unstructured data) during the “light bulb event” the contrast could not be more surprising!
If you are dealing with numbers in tables, you’re looking at column headings, product names, units and rigid time periods, so integrating various sources means that everything should be harmonised, for example:
Harmonising structured data to import it into one platform and then further manipulate it to integrate the various sources in order for meaningful analytics to be possible takes weeks, sometimes even months, compared to the 3 days to import, integrate, annotate, and explore unstructured data from various sources.
With unstructured data the integration process is simple; all data in text format can be annotated for relevance, brand, sentiment and topics in an automated way using machine learning models or taxonomies. Data in other formats (such as image or audio) can be converted into text in order for the same process to follow. This makes it possible to annotate call centre conversations or images from social media, just as easily as text in online posts and responses to open ended questions from surveys.
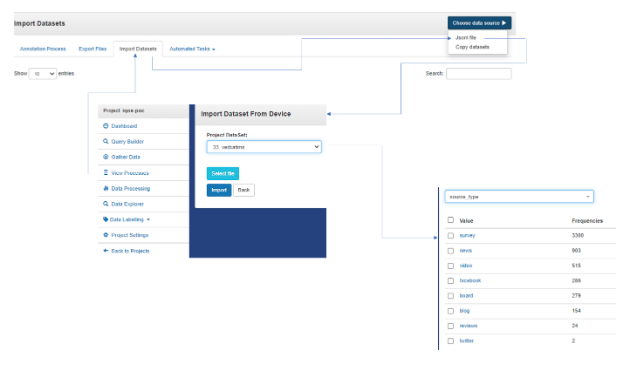
Fig. 1 Ingesting survey verbatims on listening247
The difference that makes all the difference (pun intended) when it comes to integrating structured vs unstructured data is that with the former the intelligence is already an added layer before the data fusion takes place, whilst with the latter the text is ingested and integrated before consistent intelligence is added to the dataset as a whole e.g. brands, sentiment/emotions and topics. Once the data is integrated it is already homogeneous (since it is all text) so it is straightforward to annotate it using custom or generic machine learning models and taxonomies - without having to worry about harmonisation.
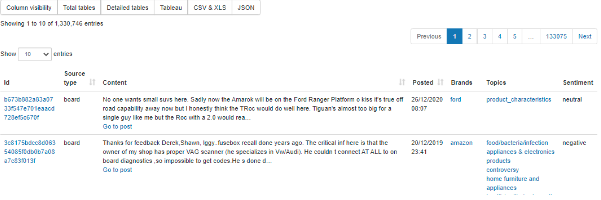
Fig 2. Annotated online posts with brand topics and sentiment on listening247 Data Explorer
There are some obstacles to integrating and annotating unstructured data other than text such as audio that needs to be transcribed and images that need to be captioned with text; only when that happens can the accurate annotation of all the integrated data sources take place. There are even more obstacles if the data to be fused involves multiple languages.

Fig. 3. Image caption example, image-to-text
Thankfully, technology is available to enable voice-to-text and image-to-text transformation, as well as accurate annotations. Without accurately adding layers of intelligence, big data and especially text is not only useless, but with the wrong labels also harmful.
A data analyst cannot be expected to read millions of online posts, but what they can do is use a smart filtering tool to drill down and explore the annotated documents (e.g. social media posts or call center threads) and discover the “gold nuggets”, the elusive actionable insights.
The future of unique and actionable insights lies in data fusion of unstructured + structured data. Some of this data will belong to the companies e.g. sales data, and some they will need to procure e.g. 3rd party online posts or survey results.
Integrating unstructured data is more effortless and straightforward than you might think. You only need a good unstructured data analytics tool.
Our contact details
Name: DigitalMR Ltd ( dba. DMR)
Address: Liberty House, 222 Regent Street, W1B 5TR, London, United Kingdom
Phone Number: 0044 203 795 4715
E-mail: info@digital-mr.com
This privacy policy was completed on 20th October 2023.
The type of personal information we collect:
We currently collect and process the following information:
Personal identifiers, contacts and characteristics (for example, name and contact details)
How we get the personal information and why we have it
Most of the personal information we process is provided to us directly by you for one of the following reasons:
We also receive personal information indirectly, from the following sources in the following scenarios:
We use the information that you have given us for:
We may share this information:
The provisions below set out the main circumstances in which DMR may disclose personal information to third parties.
DMR also disclose individually identified information to a third party in the following instances:
In addition, DMR reserves the right to allow access to DMR's systems to third parties providing technical services to DMR when such access is required to provide those services and to provide individually identifiable information to third parties who provide services on DMR's behalf. DMR require such third parties to maintain the security of personally identifiable information and use it only on DMR's behalf in connection with the provision of such services.
DMR may share the collected data along with any other relevant information which is available to the public with clients anonymously.
DMR may also disclose personally identifiable information as required by law or a competent regulatory authority.
If a government authority asks us to share information:
DMR may provide anonymous information and aggregated data about the usage of DMR's services to third parties for such purposes as DMR deems, in DMR's sole discretion, to be appropriate, but this will not include information that can be used to identify the individual.
No individual may disclose personally identifiable information to any third party unless it is with DMR's and any other relevant party's consent.
DMR never sells or shares personally identifiable information with third parties for their marketing purposes.
Third Party Processors
Our carefully selected partners and service providers may process personal information about you on our behalf as described below:
Under the UK General Data Protection Regulation (UK GDPR), the lawful bases we rely on for processing this information are:
Address: Liberty House, 222 Regent Street, W1B 5TR, London, United Kingdom
Phone Number: 0044 203 795 4715
E-mail: info@digital-mr.com
How we store your personal information
Your information is securely stored.
The security of personally identifiable information is a priority for DMR. DMR employs security measures to protect such information both online and offline from access by unauthorised persons and against unlawful processing, accidental loss, destruction and damage.
In particular, note that DMR may require (or be required) to retain certain data if it may be necessary to prevent fraud or future abuse, or for legitimate business purposes, such as analysis of aggregated, non-personally identifiable data if required for regulatory compliance purposes, or if otherwise required by law. All retained data will continue to be subject to the terms of this privacy.
We keep personal information for as long as a project is live and after that for at least 5 years. We will then dispose of your information by deleting the electronic files that contain it. Archived backups might be stored for another 5 years.
DMR will retain the information as long as the law requires. We will then dispose of personal information by deleting the data from our servers.
Your data protection rights
Under data protection law, you have rights including:
Your right of access - You have the right to ask us for copies of your personal information.
Your right to rectification - You have the right to ask us to rectify personal information you think is inaccurate. You also have the right to ask us to complete information you think is incomplete.
Your right to erasure - You have the right to ask us to erase your personal information in certain circumstances.
Your right to restriction of processing - You have the right to ask us to restrict the processing of your personal information in certain circumstances.
Your right to object to processing - You have the right to object to the processing of your personal information in certain circumstances.
Your right to data portability - You have the right to ask that we transfer the personal information you gave us to another organisation, or to you, in certain circumstances.
You are not required to pay any charge for exercising your rights. If you make a request, we have one month to respond to you.
Please contact us using the information below if you wish to make a request.
Address: Liberty House, 222 Regent Street, W1B 5TR, London, United Kingdom
Phone Number: 0044 203 795 4715
E-mail: info@digital-mr.com
How to complain
If you have any concerns about our use of your personal information, you can make a complaint to us at:
Address: Liberty House, 222 Regent Street, W1B 5TR, London, United Kingdom
Phone Number: 0044 203 795 4715
E-mail: info@digital-mr.com
You can also complain to the ICO if you are unhappy with how we have used your data.
The ICO’s address:
Information Commissioner’s Office
Wycliffe House
Water Lane
Wilmslow
Cheshire
SK9 5AF
Helpline number: 0303 123 1113
ICO website: https://www.ico.org.uk